# Building an Interactive Histogram Explorer with Streamlit
Data visualization is fundamental to understanding your datasets, and histograms are among the most powerful tools for exploring data distributions. However, creating multiple histograms with different parameters and filters often requires writing repetitive code or juggling between different tools.
That’s why I built the Histogram Explorer – a streamlined web application that lets you explore data distributions interactively through your browser. Whether you’re analyzing sample data or your own datasets, this tool makes histogram exploration intuitive and efficient. You can check out the complete project and code on GitHub.
Beyond the practical need for better data exploration tools, this project served another important purpose: me reconnecting with Streamlit. During my graduate studies, I had used Streamlit to build an interactive data analysis web application for a competition. However, after entering the workforce, I hadn’t revisited this technology stack. When I recently discovered an interesting screen time dataset shared by the data community, I saw the perfect opportunity to dust off my Streamlit skills. Instead of reaching for my go-to tool Tableau, I chose to challenge myself with Streamlit development, leveraging AI-assisted coding to accelerate the implementation process.
# Project Purpose and Goals
The Histogram Explorer was designed with a clear mission: make histogram-based data exploration accessible and interactive for everyone. The tool addresses several common pain points in data analysis:
- No coding required: Upload your data and start exploring immediately
- Interactive filtering: Apply multiple filters and see results instantly
- Flexible grouping: Compare distributions across different categories
- Professional visualizations: Generate publication-ready plots with statistical annotations
- Sample data included: Get started immediately with built-in example data
The application runs entirely in your browser, making it accessible from anywhere without complex installations or dependencies.
# Code Architecture and Implementation
Let me walk you through the key components of the application and explain how each section contributes to the overall functionality.
# Project Setup and Configuration
| |
The application starts with essential imports, combining Streamlit for the web interface, pandas for data handling, and seaborn/matplotlib for beautiful statistical visualizations. The centered layout provides a focused, clean appearance that works well across different screen sizes.
# Custom Styling and Chinese Font Support
| |
This section demonstrates thoughtful UI customization. The CSS removes Streamlit’s default colorful header decoration for a cleaner look, while the matplotlib configuration ensures proper Chinese character rendering – essential for international datasets or bilingual analysis.
# Core Visualization Function
| |
This is the heart of the visualization engine. The function creates publication-quality histograms with several key features:
- Kernel Density Estimation (KDE): The smooth curve overlay helps identify the underlying distribution shape
- Automatic Frequency Labels: Each bar displays its exact count, providing precise numerical insight
- Smart Tick Management: X-axis labels are intelligently spaced to prevent overcrowding
- Missing Data Handling:
dropna()ensures robust performance with incomplete datasets
The combination of seaborn’s statistical plotting capabilities with custom annotations creates visualizations that are both beautiful and informative.
# Flexible Data Source Management
| |
The data source selector provides maximum flexibility. Users can either explore the application immediately with sample data or upload their own files. Supporting both CSV and Excel formats covers the vast majority of common data scenarios, while the radio button interface keeps the choice clear and simple.
# Efficient Data Loading with Caching
| |
The @st.cache_data decorator is crucial for performance. It ensures data files are only loaded once, even when users interact with different controls. This caching mechanism prevents unnecessary file re-reading and keeps the application responsive, especially important for larger datasets.
# Intelligent Field Classification
| |
The application automatically distinguishes between numeric and categorical fields, presenting users with only appropriate options. This prevents common errors (like trying to create histograms of text fields) while guiding users toward meaningful analysis choices.
# Advanced Filtering System
| |
The filtering system is both powerful and user-friendly. Multiple categorical filters can be applied simultaneously, with each filter displaying its unique values in sorted order. The two-column layout maximizes screen space while maintaining readability, and the default selection ensures users see results immediately.
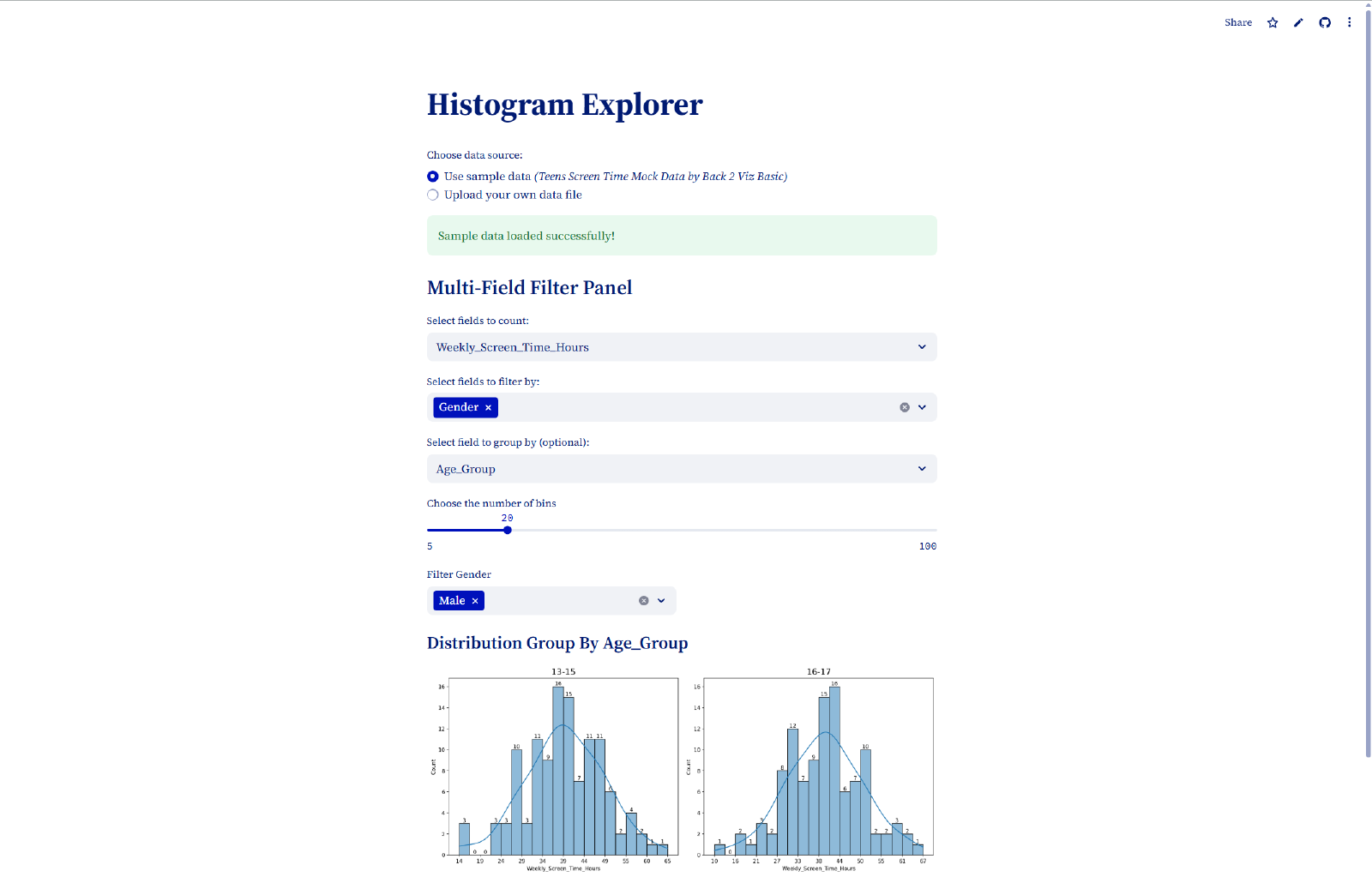
# Dynamic Group-Based Analysis
| |
This is where the application really shines. Users can choose to view either a single histogram of all filtered data or multiple histograms grouped by a categorical variable. The grouped view automatically calculates the optimal subplot layout and handles edge cases like unused subplot areas.
The intelligent field filtering ensures that grouping fields don’t conflict with active filters, preventing logical inconsistencies in the analysis.
# Professional Layout and Spacing
| |
The layout parameters ensure that multiple histograms display clearly without overlapping labels or titles. This attention to visual detail makes the difference between amateur-looking plots and publication-ready visualizations.
# Conclusion
The Histogram Explorer demonstrates how modern web frameworks like Streamlit can make powerful data analysis accessible to everyone. By combining intuitive interface design with robust statistical visualization capabilities, this project bridges the gap between complex analysis and user-friendly exploration.
For me personally, this project was a successful return to Streamlit development, proving that with the right tools and AI assistance, we can quickly build meaningful applications that solve real data analysis challenges. The combination of rediscovering past skills and leveraging modern development approaches made this both a technical and learning success.
Ready to explore your data distributions? Check out the Histogram Explorer on GitHub and start discovering patterns in your datasets!